Motivation
AI tools are increasingly used as common inputs into economic decisions. Analysts, firms, consumers, and workers may consult similar models, trained on similar data, and receive highly correlated recommendations. When many people then take the same action, observers face a basic inference problem: does the public run summarize many independent pieces of evidence, or does it mostly repeat one shared AI forecast?
This ambiguity creates a trade-off. Shared AI use correlates actions and can accelerate herding. At the same time, because a public run may be generated by repeated exposure to the same signal, the run becomes less persuasive as independent evidence. Bayesian decision makers may therefore put more weight on their own private signals than they would in a standard cascade.
Model
The state is , with a symmetric prior. A continuum of possible histories is generated by a sequence of short-lived agents who each choose between actions and . With probability , an agent is an AI-user type and observes the same shared AI signal , drawn once at the start with precision . With probability , the agent is an independent-agent type and observes an independent private signal with precision .
Signals and types are private, while actions are public. Let denote the public belief that the state is high before agent acts. This marginal state belief is part of a larger public posterior over both the payoff state and the realized AI signal. That joint belief is essential: a run of identical actions may raise the probability that the state is high, but it may also raise the probability that many previous agents were simply reacting to the same AI signal.
Decision rules differ by type. Independent agents compare with their own signal and follow their signal as long as remains inside the cascade interval . Once the public belief exits this interval, their action no longer reveals their signal. AI users instead condition on the public history and on their realized shared signal, so their actions can reveal, conceal, or amplify that common source.
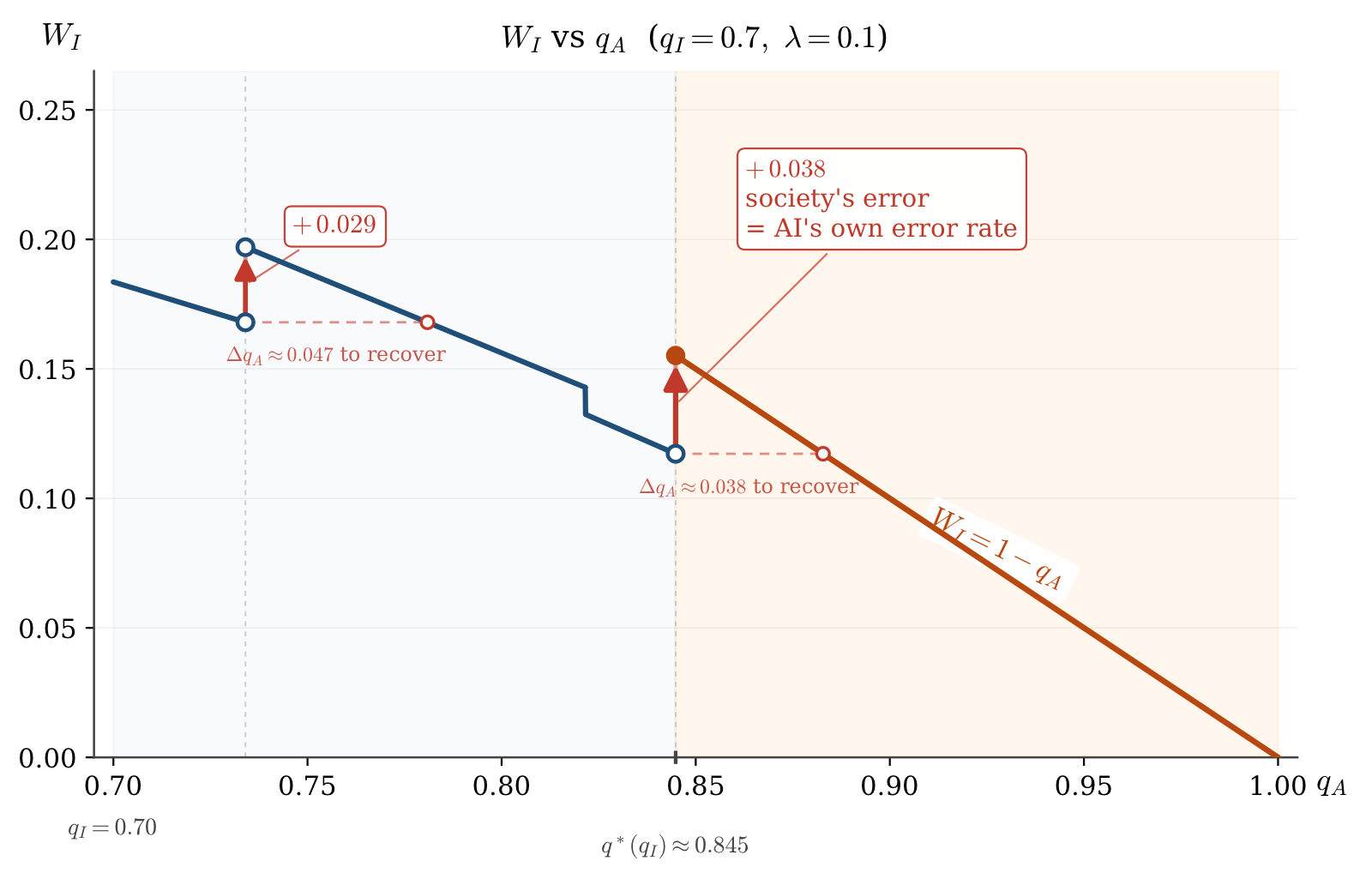
The equilibrium object is a perfect Bayesian equilibrium of this learning process. The main statistic is the long-run probability that independent agents eventually take the wrong action in a cascade, , as AI precision and adoption vary.
Main results
Low-precision AI
When the AI signal is less precise than independent private signals, AI users are more prone to herd on the public history. Their actions then stop revealing the shared AI signal. A public run mixes independent confirmations with undisclosed repetition of the same source, so wider AI adoption raises the risk of an incorrect cascade.
High-precision AI
When the AI signal is sufficiently precise, an AI user whose signal contradicts the prevailing public run reveals the shared signal. Once revealed, the signal is strong enough to determine the eventual cascade. The long-run wrong-cascade probability becomes : society is wrong exactly when the shared AI signal is wrong.
Intermediate precision
Between these cases, revealing the AI signal is not enough to settle the cascade. Independent signals still matter, but only through a finite hitting problem. The wrong-cascade probability is piecewise linear in AI precision and can jump upward at trigger boundaries. Better AI can therefore locally degrade social learning.
Takeaway
AI precision alone is not enough to evaluate the social value of AI. The same technology can improve individual decisions while weakening the informational content of public histories. What matters is the interaction between precision, adoption, and whether agents are learning from independent evidence or from a common source.